Advanced OpenGL
After reading both papers I realized that the Hadwiger paper was limited by their ability to produce nodes in their deep shadow map by the hardware. The method required the fragment shader to write to multiple frame buffers to write out nodes and then use a multi-pass approach to generate all the nodes required for the deep shadow map.
I decided to use CUDA instead, which wouldn’t handicap me to use a multi-pass process. Instead, I could do a context switch from CUDA to OpenGL and map the linear array I had instantiated in CUDA to a 3D texture in OpenGL. There were a few hiccups.
-
Because of the two separate contexts (CUDA and OpenGL), the 1D array I was created in CUDA actually wasn’t really a pointer to a 3D texture in OpenGL. In fact, on the context switch, the data was copied. It is exceptionally fast since its a VRAM to VRAM, but nonetheless, still a copy. I worked around this by just writing a ray caster in CUDA (which I later found out is also available in the CUDA SDK) and only copying a 512 x 512 image back and forth between CUDA and OpenGL. However, in DirectX you can create “pointers”, so no memory would need to be copied over. Also, there’s a texture pointer in OpenGL that’s available, but I was never able to get it to function correctly. I would prefer that I generate the deep shadow map in CUDA and use Cg or GLSL to do the volume rendering, but as it is right now, CUDA does the volume rendering.
-
My workstation has a 9800 GX2 which is a dual GPU card. That’s awesome, except CUDA decided to copy all the data down to the “host” and then copy it back to the device when copying the data. This was atrociously slow, but solved by turning off one of the GPUs. This is a known bug in CUDA.
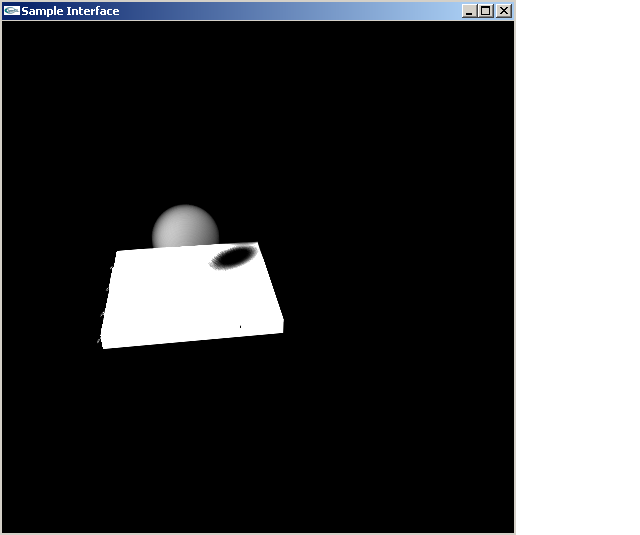
~20 fps, 512x512 deep shadow map and a 512x512 viewport.
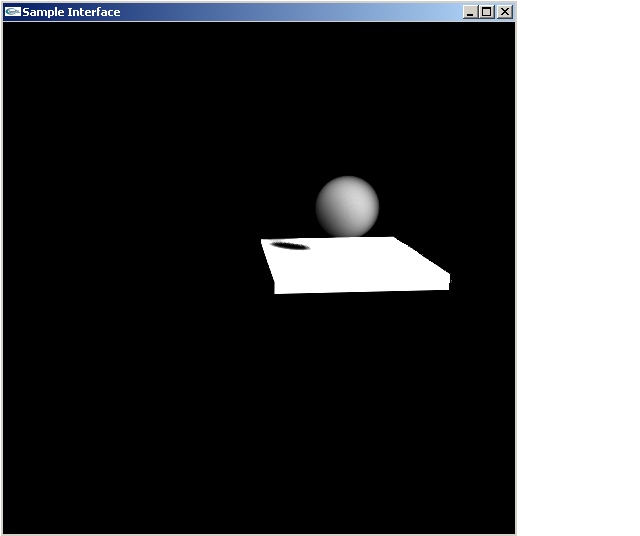
~20 fps, 512x512 deep shadow map and a 512x512 viewport.
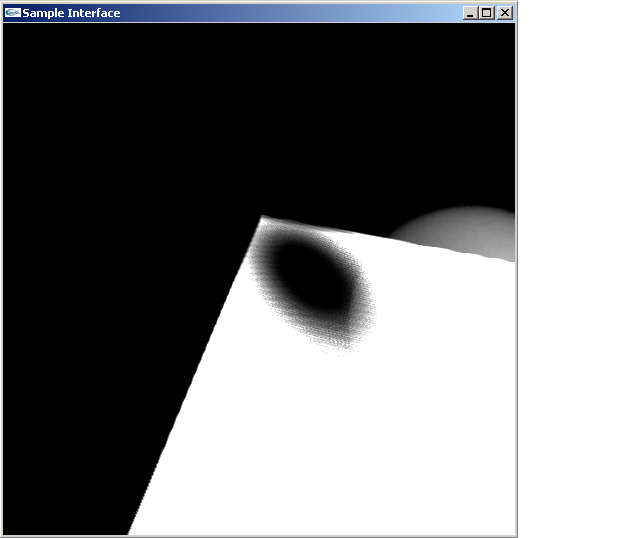
~9 fps, 512x512 deep shadow map and a 512x512 viewport.
As you can see in the third image, there’s some pretty bad sampling artifacts. Although I am using a a 512x512 box to do my deep shadow map for this image, its unclear to me how many rays are actually used to create the shadow. After all, there are more rays that miss the shadow volume completely than actually hit the shadow volume, so much of the 512x512 is hitting empty space.
Further, I deviated from the the lookup used in the paper mostly because the way I thought they did it lead to an exceptionally slow (less than 1 fps) shadow volume, so what I do instead is shoot ray back towards the light and figure out where it hits the light camera viewport, and then project that into the viewport so I can figure out which ray that was built is closest. I think that’s another reason why the third images has such poor artifacts.
Finally, things that still need to get done. I still don’t have a good compression strategy, which I would hope would decrease the amount of memory is use (currently 512^3 for this sample). Also, I would like to figure out a better way to do the look up for the deep shadow map. Also, switch from copying over essentially a frame buffer to using Cg/GLSL instead.