Octree and voxelization
First, I need to know how deep the octree needs to be. So, I threw the mesh into a GPU octree and it never returned. Okay, so I threw it in a CPU octree, and it never returned. Hmmm… turns out there are duplicate faces and vertices. Fixed those, now both the GPU and the CPU version of the octree return…a depth of 17. That means I’m looking at a resolution of 2^17 or 131072^3. Yikes. After looking at some of the octree and voxelization results though, I think we can do something like 2048^3.


The top image is for an octree at the lowest level, where the level is 10 (2^10 = 1024)
The bottom image is for an octree at the lowest level, where the level is 11 (2^11 = 2048).
It’s easy to see that there isn’t a consistent coverage at this level.


The top image is if we stop where a bounding box is a leaf. The bottom image is zoomed in closer. You can see there are varying levels of the mesh, but the vary levels have little do with the curvature and in one case, the density, of the mesh.
These random varying octree cells are no good. I rely on the cells to create good embeddings. I’d rather have a consistent coverage. So, let’s try voxelization.
I started with this paper:
Out-of-core construction of sparse voxel octrees
and this code:
I first parallelized it on the CPU then did it in CUDA.
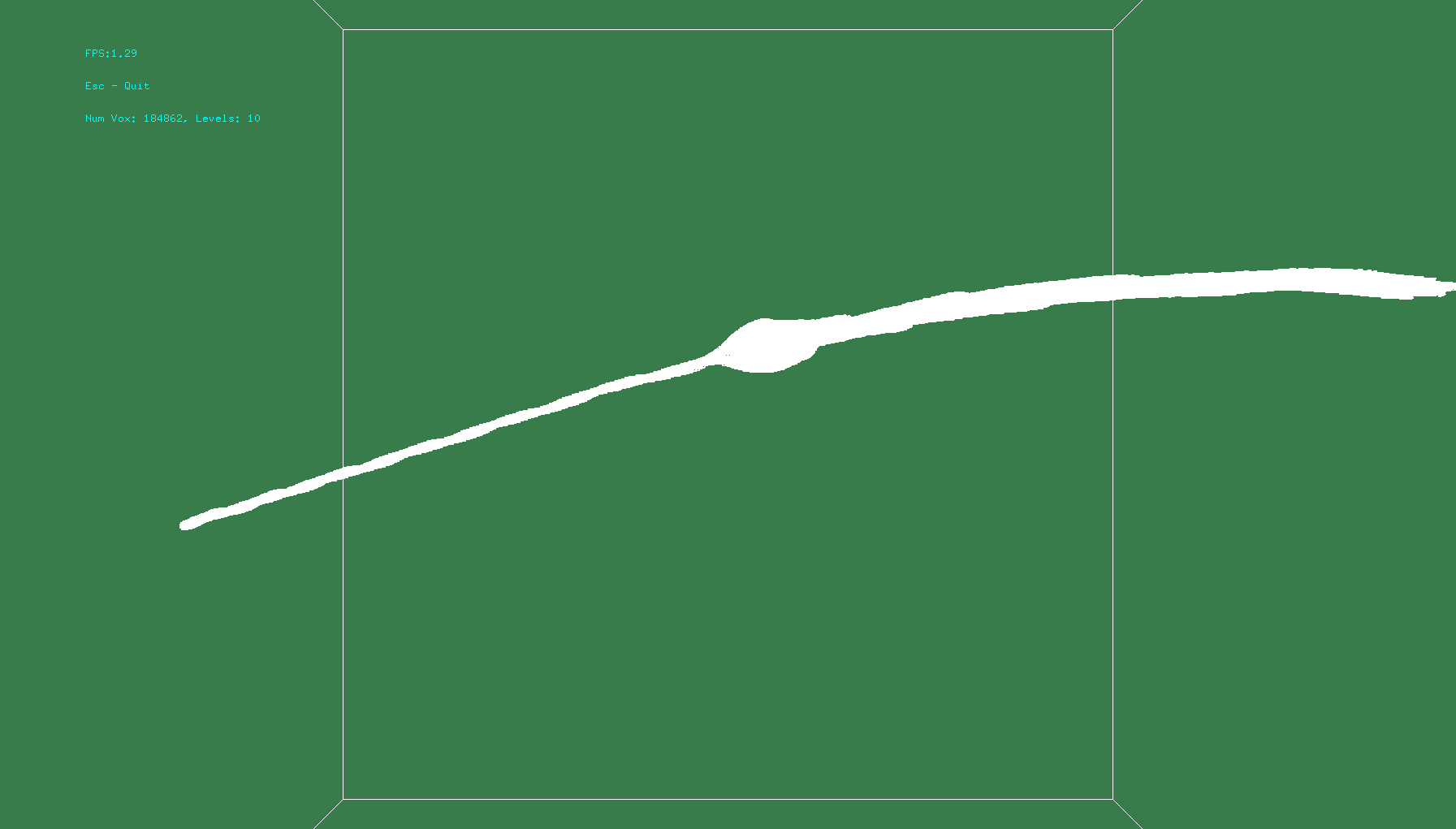
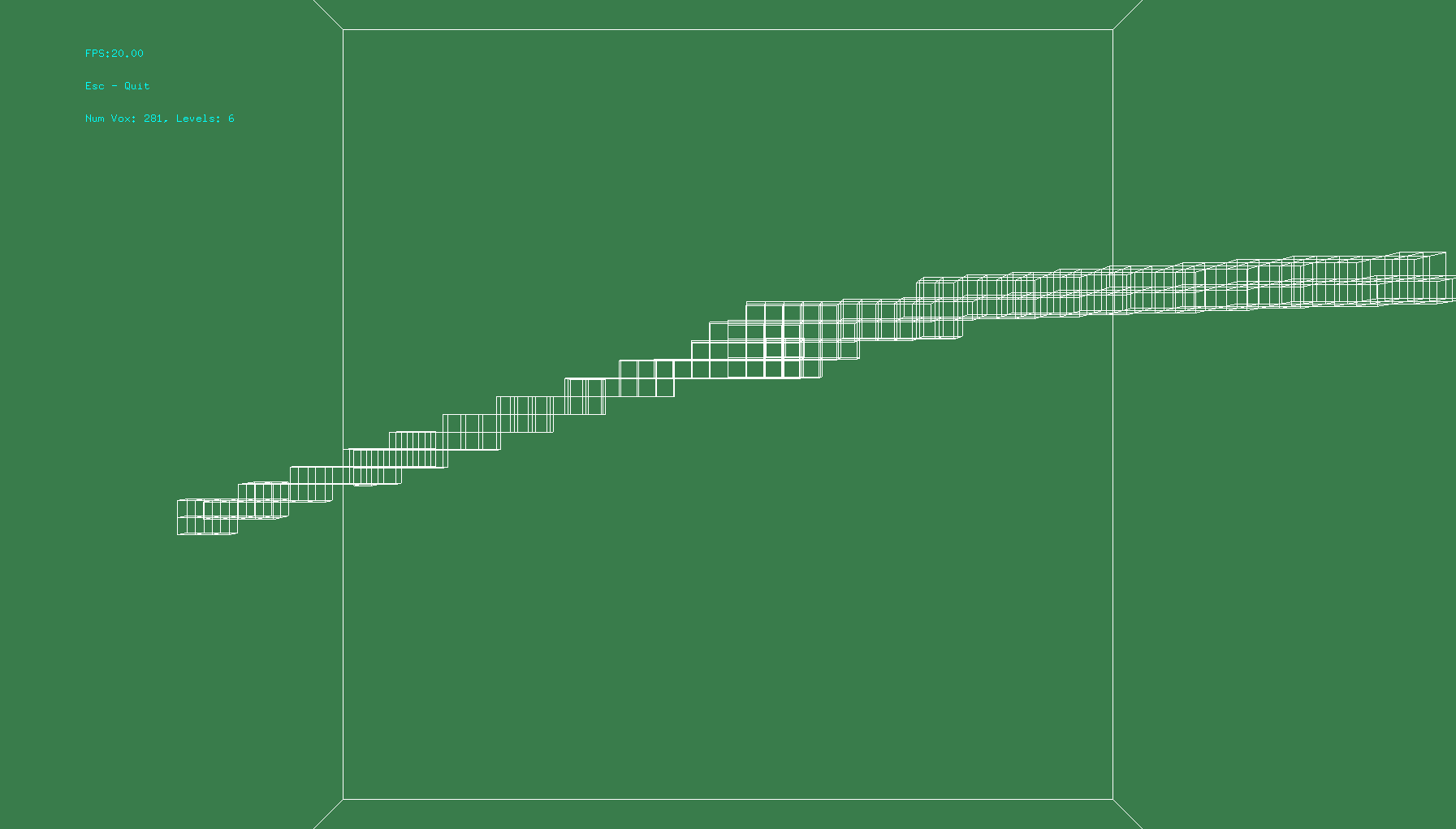
The top image is voxelization with the level=10. However, it’s difficult to discern anything, so the bottom image is level=6. The coverage is consistent, and near the level I want.
The problem is the octree on the GPU is fast and only relies on the vertices.
The voxelization needs to check the faces and determine whether the
voxel cell intersects it, so is slower. How much slower? Just the algorithm, on the GPU,
takes approximately 0.388 seconds when the level is 2048. In total, it takes 0.74 seconds.
Why is this so slow on the GPU?
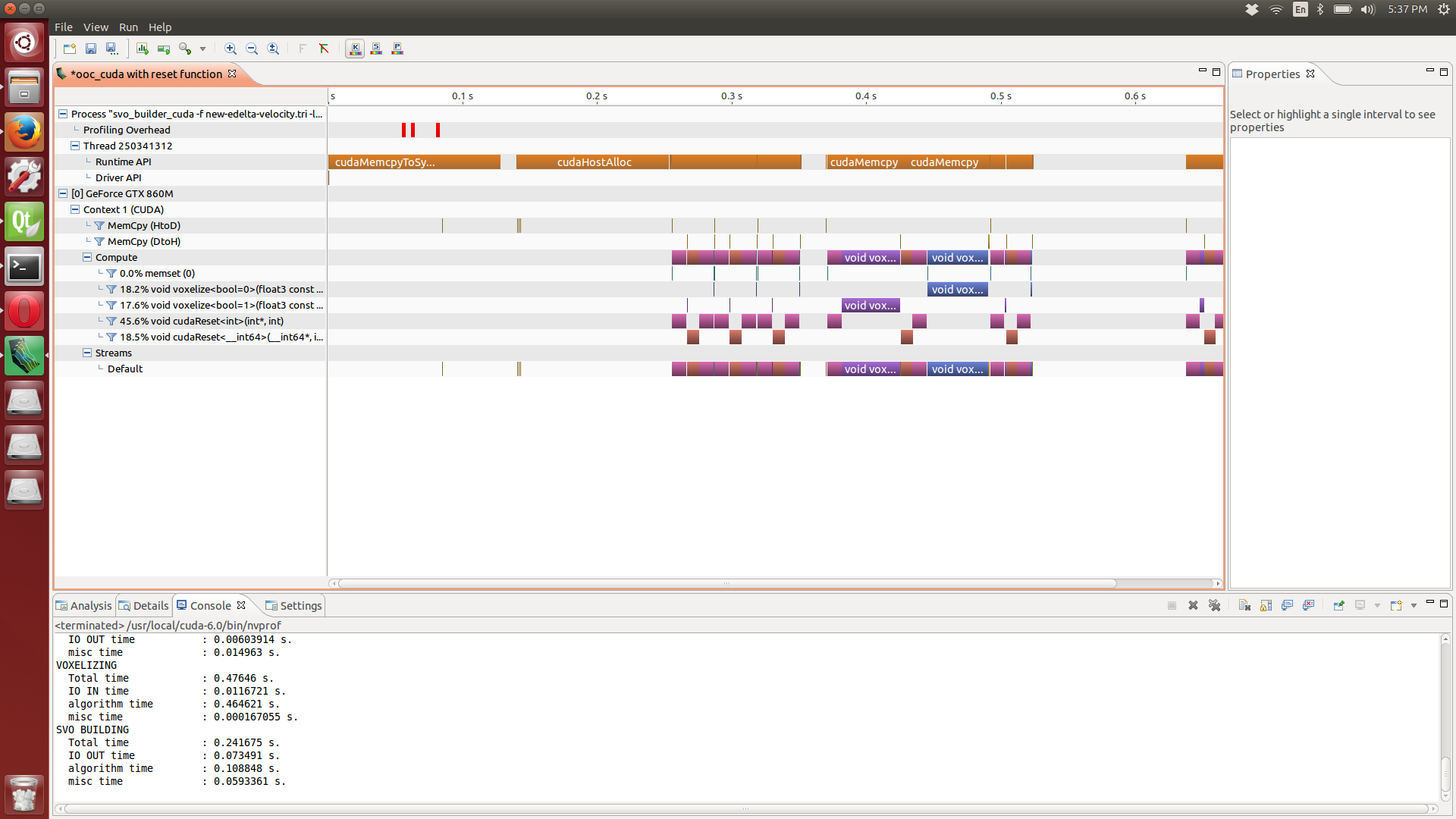
This is a profile of the voxelization in CUDA on a Acer V15 Nitro Black Edition (i7-4720HQ with an Nvidia GTX-860m with 4GB VRAM). It is dominated by cudaReset and cudaMemcpy, where cudaReset is a kernel simply sets an array to 0 (this is faster than cudaMemset). 64% of the time is spent running cudaReset. Previously, cudaMemset took 77% of the time.
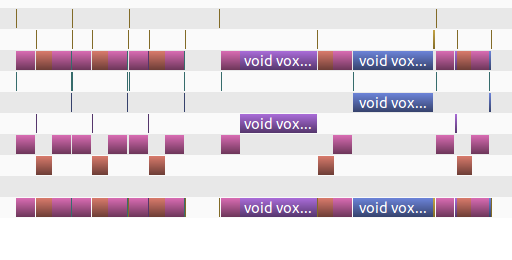
Breaking the processing down, the image above is zoomed.
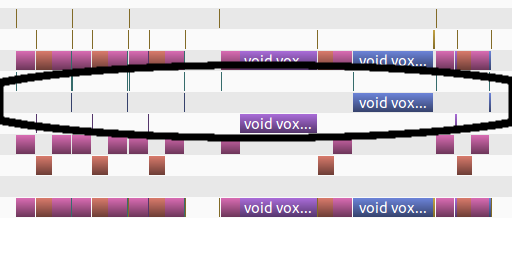
Here, the computation blocks are circled. As you can see, 4 of the five that are highlighted are slivers.
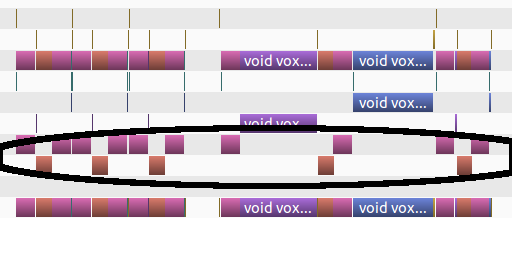
Here, the copying and setting the memory to zero is highlighted. The time to copy back data as well as reset arrays dominates the computation.
The 2048^3 block is broken down into 8 regions and each region is processed separately. This unfortunately leaves the workload unbalanced, which we can see because only one of the eight blocks is visible in the graph (the other 7 are either completely absent or take so little time that they are slivers in the graph).
The unbalanced workload is the achille’s heel of this. But, the only way to get 2048^3 is to break up the grid. The copying and resetting kill performance.
The CUDA version is only a tenth of a second faster than a multi-core, SSE 4.2 version I also wrote.
Moving foward, if I stay with the voxelization at 2048^3, I think it would be better to stick with the CPU version, and have the time=t+1 voxelizer run as the CUDA advection at time=t is run.